Before you start investing
Before you start investing make sure you go through the following questions. These check list is taken from freefincal [1]with some addition.
- Is your Life Secured (Term Life ) ?
- Have you added nominee for all of your investment and accounts ?
- Have you involved your spouse in financial planning ?
- Is your family insured with health insurance ? (independent of the Employer health insurance)
- How ready are you to handle the emergency expenses ?
- How many months of money should be your emergency fund?
- What if your emergency funds gets depleted ? is there any buffer
- What is your net worth ?
- Have you listed/though through of all the Goals ? Short Term (< 5 years) , intermediate (5-10 years) and long Term(> 10 years)
- Have you decided the asset allocation for intermediate and long term goals
- Do you know how much you need to save for each of them ?
- If there is short fall how are you going to manage it ?
- Are you making separate investment for your children ?
- have you opened savings bank account and keeping track of it ?
- have you started PPF/SSY for them ?
Saving Money
Expenses = Income – Savings
Savings should be the top priority . How to save or how much to save is not as important as consistency in saving. Consistency beats the inflation , it beats the return on voluntary savings and most importantly it beats the worry of the future.
Goal Based Investing
Once you make up your mind on savings the immediate next step should be planning . However planning can be overwhelming . So to simplify the planning part we must first set some goals. These goals are some general milestones of life , responsibilities or even the your ambitions that you want to achieve in life. This is called as goal based investment
Goal based investment [2] gives you clear idea about many things such as how much wealth (money) you need to achieve the goal , what is time horizon for it etc. we will go deeper into this as we move forward. By setting up a goal for investment we knowlingly define the following things
Setting up a GOAL should answers following things
- How much money you need to achieve it ? – let’s call the target amount
- What is the time horizon to achieve this target amount ? – lets call it duration
- How much money you can invest from today to achieve this target amount ? (irrespective of the investment returns)
- What is you risk appetite ?
- are you conservative investor ?
- are you willing to take some risk ?
- Do you prefer high risk high risk high reward investment
- Depending on your risk appetite , decide the average return range
- This step can be difficult hence deciding the underlying investment asset and its respective average return can be considered
By considering above points one can start investment to achieve the defined GOAL .
Now we know what GOAL based investment is let’s sett how to priorities them.
What Goals you should define ?
It is easy to say “define your goal” however it is difficult to define it and even more difficult to priorities it. So to help you defining and priorities of the goals here is the simple diagram that categories the goals into 3 buckets.
- Security
- Stability
- Ambition
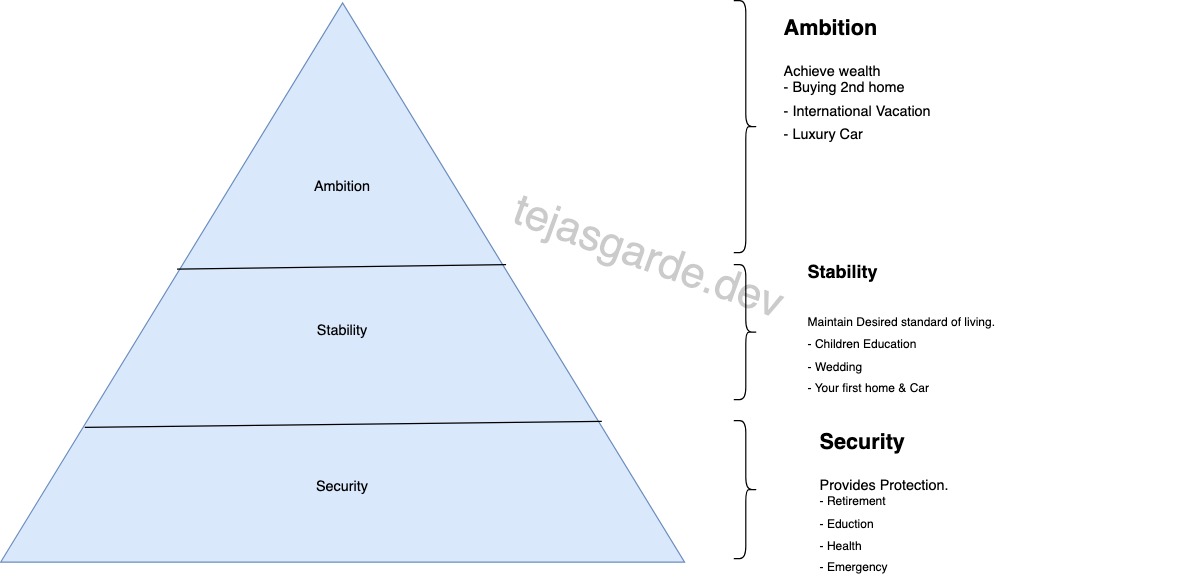
It is evident that the some financial goals should be prioritises before others . Hence as we can see in diagram , the Security is at the base of the pyramid. Then the Stability and at last the Ambition. Let’s go one by one
Security
This bucket of investment GOAL provides a protection to your life. It is obvious that we should first start investing for some aspects of our life that are essentials. To list down the few.
- Retirement
- Health for Family
- Emergency Funds
- Education
My personal opinion is that emergency funds should be achieved first even bore any other goal. This will give you not only the protection from the unknown emergencies but also the confidence to invest your money in other goals.
So while you plan your investment , set aside the money to achieve these goals first and then go for the goals of the Stability and Ambition.
Stability
These are the set of goals which maintains the desired standard of living. These are goals helps you to have stable but fulfilling life. To list down the few.
- Children’s higher education
- Buying your fist home
- Buying family car
- Wedding
These financial goals are usually mid to long term goals with somewhat big corpus. The idea here is to have sufficient target money should be built such that you don’t have to take any loans .
Ambition
These set of goals defines the luxury in your life. So be sure you are contributing or achieved your security and stability goals first. To list down the few.
- Buying holiday or 2nd home
- International vacation every year
- Luxury car
Credits:
The purpose of this blog post is to educate readers on managing personal finances. Credit for the content goes to the original authors.
[1]. freefincal – By M Pattabiraman
[2]. Coffee Can Investing Book by Pranab Uniyal, Rakshit Ranjan, and Saurabh Mukherjea