Continuing the Spring WeFlux series , here now we will cover the Reactive Repository. Here is the link for Part-2 where we have covered the controller part.
Why we need Reactive Repository
All the database calls using JDBC drivers are blocking in nature. That means a thread that calls the database wait until the database return any result or timeouts. So this is huge waste of the resource , thread which is just waiting ideally can be used for better purpose . So what are the different solutions for this problem ? There can be number of solutions but we will discuss below two and implement only one .
Using CompletableFuture and ThreadPool
Using Reactive Relational Database Connectivity (R2DBC) .
CompletableFuture and ThreadPool
This way of executing database query is not a non-blocking way but it separates the blocking query into different execution context. Here we can create a Thread Pool and use that pool with CompletableFuture to execute database query something like this.
Executor executor = Executors.newFixedThreadPool(10);
CompletableFuture future = CompletableFuture.supplyAsync(() -> {
String sql = "SELECT * FROM users";
ResultSet rs = stmt.executeQuery(sql);
//iterate over result set and return result
User user = new User();
while(rs.next()){
user.setName(rs.getString("name"));
user.setId(rs.getInt("id"));
}
return user;
}, executor);
Using Reactive Relational Database Connectivity (R2DBC)
R2DBC is a project that enables us to use the reactive programming API to connect to Relational Database. Until now it is not possible to use JDBC as those are blocking API’s. We can use the R2DBC project along with Spring data to talk to Relational Database. We are continuing example for last post and now we will add this R2DBC project , but for that we will have to add the following dependencies.
By adding above dependency we have all that we need to use the reactive API to access the relational database . In this case we are using R2DBC and Spring Data R2DBC
Data Base Configuration
For R2DBC to work we will have to add certain configuration , fo this we will add a DataBaseConfiguration class that creates a Spring Bean of ConnectionFactory this bean will have r2dbc connection url , data base name etc. We will create this Configuration class by extending AbstractR2dbcConfiguration. Below is the code for the same.
@org.springframework.context.annotation.Configuration
@ComponentScan("dev.tgarde.webflux")
@EnableWebFlux
@EnableR2dbcRepositories
public class DataBaseConfiguration extends AbstractR2dbcConfiguration {
@Bean
public ConnectionFactory connectionFactory() {
ConnectionFactory connectionFactory = ConnectionFactories.get(
"r2dbcs:mysql://localhost:3306/ExampleDB?"+
"zeroDate=use_round&"+
"sslMode=disabled");
return connectionFactory;
}
}
@EnableR2dbcRepositories Annotation is used activate reactive relational repositories using R2DBC.
Reactive Repository
ReactiveRepository are similar to JPA repository, it can be created by simple interface and extending ReactiveCrudRepository interface with Entity class name and primary key type.
public interface UserRepository extends ReactiveCrudRepository<User, Long> {
@Query("SELECT * FROM user WHERE firstname = :firstname") Flux<User> findByFirstName(String firstname); }
Now with above repository implementation we the only difference in it compared to JpaRepository is that the return type of the Interface is of type Reactive in this case Flux or Mono.
We can call above repository from our UserService and just use it the way we use JpaRepository.
In Micro service architecture , we generally have a dedicated database schema for each service (though there are exceptions). Each service is then responsible for managing data from its data base and then taking to or responding to other micro services .
Now since we have different data bases schema the data access layer for each micro service is different . But that doesn’t mean data is not related. We can have entities that are related across schemas.
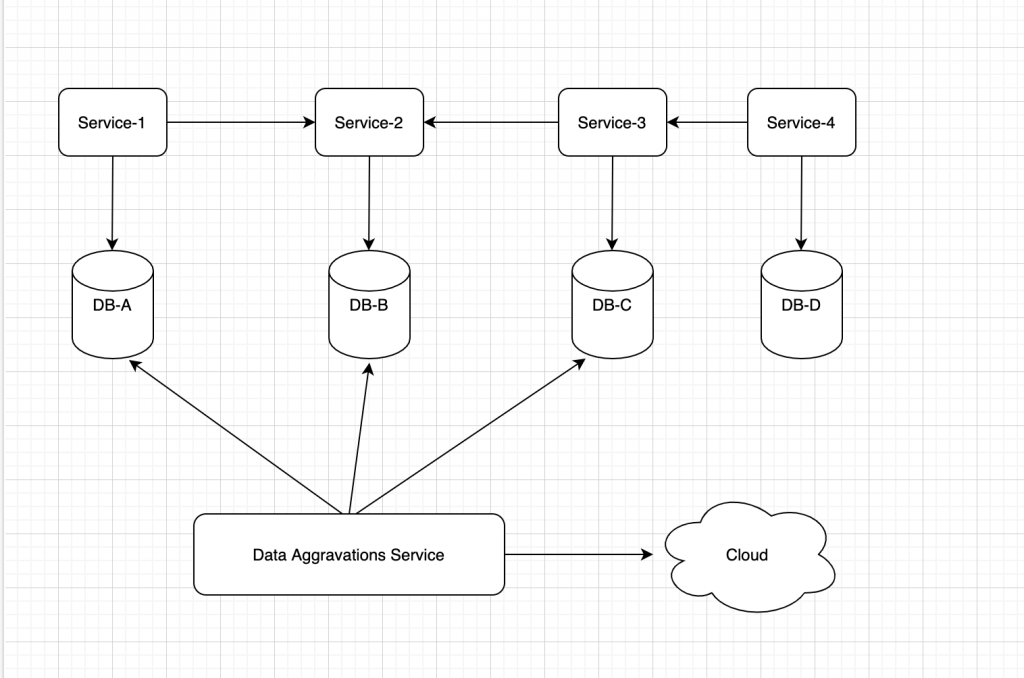
Consider below diagram , few micro services interacting with each other (service discover not shown for simplicity) . Data Aggregation Service interacts with three different data base schemas and processing it and sending over network or cloud service like SNS or SQS or simply sending it to any third party consumer.
Microservice interaction
This Data Aggregation service should be able to access data from multiple databases schemas as per requirement but with minimal data base trips. SQL query over multiple data bases schemas is possible with joins but what about data access layer ? We know when using ORM we can easily access related data from different tables when relations are defined in Entity classes or configuration depending on which implementation of JPA you are using . For example lets say for online shopping site we have Users table and Addresses table and they have one to many relation. So using JPA 2 Hibernate implementation i’ss quite simple to define this relation on Entity level and then extract Addresses using User we all know that very well.
Here is scenario, Let’s say we have micro-service-1 which handles users and address operation but another micro-service-2 handles reviews given by User and uses Reviews table . A Separate micro-service-3 handles Products which can include Type of product , its manufacturer and lot more but for simplicity we will consider this service handles only one table as of now called products
There is requirement of another micro-service say data aggregation service which should fetch data from Users,Products and Reviews tables and push this data to cloud service for analytics . Lets Start by creating schema , we are just crating micro-service-3 data access layer to understand how JPA can be used to access related data across the schema’s. For simpler explanation just assume micro-service-1 and micro-service-2 are populating their respective tables and our service has read-only access to those tables. We are populating tables with insert statements. Create 3 schema’s product_service, user_service, review_service and run below sql queries.
-- products service data base tables
CREATE TABLE `product_service`.`products` (
id bigint(20) NOT NULL AUTO_INCREMENT,
name varchar(30) NOT NULL,
manufacturer varchar(30) NOT NULL,
type varchar(30) NOT NULL,
PRIMARY KEY (id)
);
-- user service data base tables
CREATE TABLE `user_service`.`users` (
id bigint(20) NOT NULL AUTO_INCREMENT,
first_name VARCHAR(30) NOT NULL,
last_name VARCHAR(30) NOT NULL,
PRIMARY KEY (id)
);
CREATE TABLE `user_service`.`addresses` (
id bigint(20) NOT NULL AUTO_INCREMENT,
user_id bigint(20),
street varchar(30) NOT NULL,
city varchar(30) NOT NULL,
state varchar(30) NOT NULL,
PRIMARY KEY (id),
FOREIGN KEY (user_id) REFERENCES users (id) ON DELETE CASCADE
);
-- reviews service data base tables
CREATE TABLE `review_service`.`reviews` (
id bigint(20) NOT NULL AUTO_INCREMENT,
user_id bigint(20),
content varchar(255),
published_date timestamp DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id)
);
-- Insert Data
INSERT INTO `product_service`.`products` (name,manufacturer, type)
values ('iPhone-11', 'Apple','mobile');
INSERT INTO `user_service`.`users` (first_name,last_name)
values ('sherlock', 'holmes');
INSERT INTO `user_service`.`addresses` (user_id,street,city,state)
values (1,'South Lake Avenue', 'Pasadena','CA');
INSERT INTO `review_service`.`reviews` (user_id,product_id,content)
values (1,1,'best iPhone ever');
-- Check All Tabled
select * from `product_service`.`products`;
select * from `user_service`.`users`;
select * from `user_service`.`addresses`;
select * from `review_service`.`reviews`;
--- Query to Fetch All Data for User including reviews
select product.name , product.manufacturer, user.first_name , user.last_name,
address.street, address.city, review.content, review.published_date
from `product_service`.`products` `product`
INNER JOIN `review_service`.`reviews` `review` ON `review`.`product_id`=`product`.`id`
INNER JOIN `user_service`.`users` user ON `user`.`id` = `review`.`user_id`
INNER JOIN `user_service`.`addresses` `address` ON `address`.`user_id`=`user`.`id`
where user.id = 1;
product_service schema has Products table that has details of each product. user_service schema has users and addresses and review_service has reviews tables containing reviews of the .
The last query in above section is our requirement. We need to fetch data from multiple schema with given userId and get result from all the tables mentioned below. Since these schemas are different there is no direct JPA relation between them and that of the result we want instead we need to defined it . But first lets do some basics stuff. We need pojo’s for the Tables, we also need EntityManager , TransactionManager for each schema and finally we need Repository classes . All of this code is present at https://github.com/tejasgrd/jpa-multi-schema-access . We will take example of each here for understanding rest of the code is on similar lines.
Users class with use of Lombok and javax.persistence annotations
@Bean public JpaTransactionManager usersTransactionManager(final JpaProperties usersJpaProperties) { return new JpaTransactionManager(usersEntityManager(usersJpaProperties).getObject()); } }
Now to run required query we have to run it as native query. We also have to map the result of the query to some object representing the variables equivalent to what we have in select query . So lets first create class representing what we have in select query ReviewsByUser.java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class ReviewsByUser {
String name;
String manufacturer;
String first_name;
String last_name;
String street;
String city;
String content;
Date published_date;
}
These are all the fields which are part of select statement . Note that column names from select query and name of the variables are not the same but one thing we need to be careful here that the type of the variables should be exactly similar to what we have in Hibernate domain objects.
Let’s move ahead , now we need to define native query . How we define it and where we have to define it . So we usually define it on domain class and in this case we are going to define it in Products class. What else ? we also have to map the result to class we already defined for that we will have to use annotation and provide it class who’s object represent the result from query. So lets first get to know these annotations that we are going to define on Product class
NamedNativesQueries are defined with annotation as below , here we have only one.
@NamedNativeQueries({
@NamedNativeQuery(
name = "<name of query>",
query = "<query goes here>",
resultSetMapping= "<result set mapping>"
)
})
To map the result of NamedNative queries we have to provide another annotation @SqlResultSetMapping and below is the format for this
So Result from Native query are mapped using resultSetMapping and name , the resultSetMapping in @NamedNativeQuery should be same as that of name in @SqlResultSetMapping . class is used to define class that represents the result from native query. Make sure that the class has constructor with the columns defined in e@ConstructorResult column . Here is the complete Product class which has above two annotations.
Note how results are mapped using same name and @ConstuctorResult has columns defined with types . Now there is still one step left here . As we are using repository we have to just define method in repository class and call it , JPA will call the invoke native query and return result .
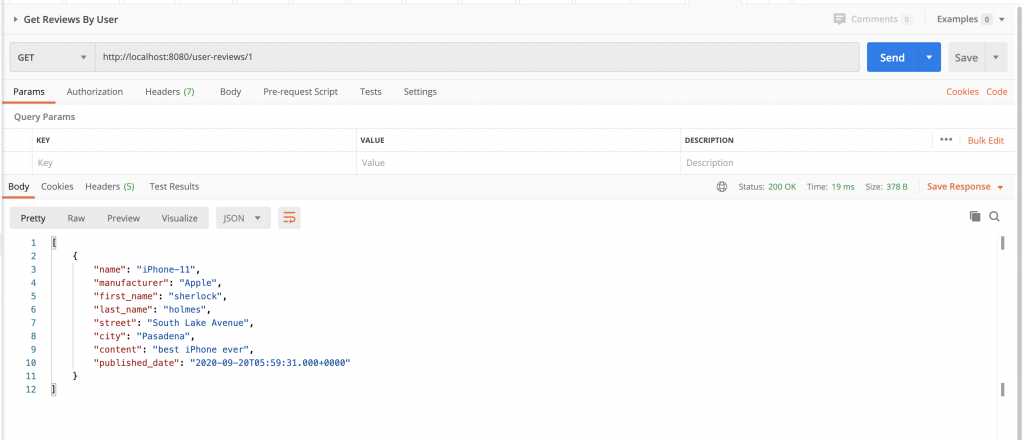
Notice the name from @NamedNativeQuery and name of the method in repository are same and it has to be like this then only JPA will figure out which @NamedNativeQuery to invoke. Below is result from PostMan . We have just added @Controller which calls this method on GET request.